Pagination best practices for ecommerce websites
Key takeaways:
- Incorrect or poor pagination can lead to crawling and indexing issues.
- There is no perfect way to implement pagination – each strategy has benefits and disadvantages.
- Do not canonicalize paginated URLs to a root page.
- Do not canonicalize paginated URLs to a ‘view all’ URL.
- Do not block search engines from crawling pagination URLs via robots.txt.
- Consider indexing all pagination URLs, or partly indexing of pagination URLS, or having a process for removing older pagination URLs.
This guide is a summary of a presentation by Jes Scholz, Group CMO at Ringier.
Let’s get started.
To skip straight to the solution, click here.
The problem.
In 2011, Google implemented the link attributes “rel=prev” and “rel=next” to help consolidate all indexing signals and links into one page part of a pagination series. And for many years, SEOs thought by using rel=prev and rel=next was fine.
Things were not fine.
In 2019, a Google spokesperson disclosed that had not used rel=prev and rel=next as an indexing signal for a few years (source). As a result, this has thrown a lot of large websites into a pickle.
Without rel=prev/next, pagination series can create crawling and indexing complications and this can have a significant impact on your organic visibility and sales.
The solution(s).
There is no one-size-fits-all solution and each of the following strategies have crawling/indexing benefits, different ongoing monitoring requirements, and their own unique crawling/indexing drawbacks.
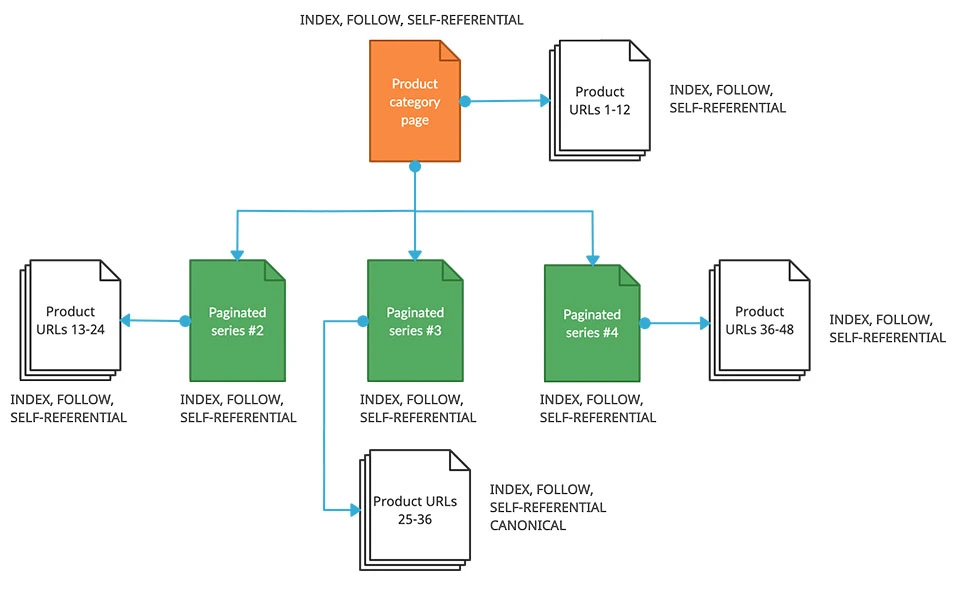
1. Index all pagination URLs and make them self-referencing.
This strategy is best for sites that want a simple plan of attack by letting Google index everything.
Benefits:
- Internal linking exists for deep URLs.
- Deeper (older) URLs have the ability to rank on Search.
Disadvantages:
- Each URL (paginated or otherwise) on your ecommerce site will be treated the same by a search engine.
- This means that paginated series are competing against the root page and this may be suboptimal for user experience.
- Ignores quality of content.
- You will still have hundreds if not thousands of indexable paginated URLs. Depending on the size of your site this may have a negative impact on the crawling and indexing of your URLs.
How to do this:
- Each paginated URL is self-referencing and indexable to search engines (i.e., avoid nofollow and noindex meta tags, ensure each URL has a self-referential canonical tag).
- Implement a process that rewrites the page title, meta description and H1 of paginated URLs to de-optimize them for the target keyword.
- Do not include context-rich or keyword-rich content on paginated URLs. Reserve these on-page SEO elements on the root page only.
- Make sure that anyone with publishing privileges is adequately educated and trained on how to implement these when adding new products to your site.
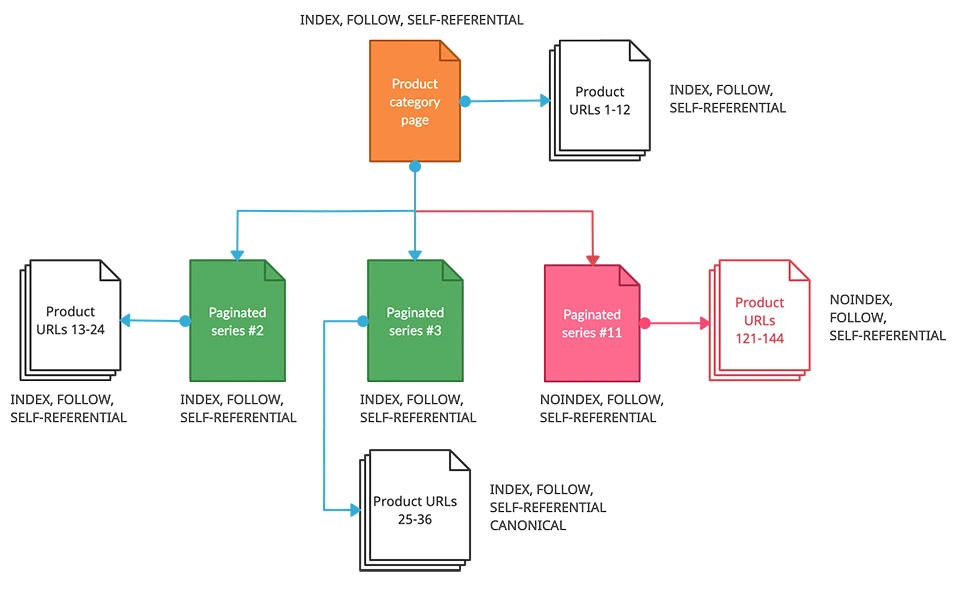
2. Index a selection of most recent pagination URLs.
This strategy is best for ecommerce sites that do not restock older products and are constantly bringing new products to their store. For example, a marketplace with UGC listings is a prime example where you may not want older listings to found on Google.
Benefits:
- Index bloat is reduced by removing older products and their URLs by signalling to the crawler that older URLs should not be indexed.
- Only newer products are indexed.
- You control which product URLs are prioritized for SERP display and organic traffic.
Disadvantages:
- Older pages/products will not show up in Google Search.
- Noindexing older URLs reduces the number of internal links and link equity to deeper/older product URLs are lost.
How to do this:
Implement a rule so that pagination pages past 10 do not get indexed. This means applying a noindex metatag to all the pagination URLS that are greater than 10.
3. Index URLs based on context and search intent.
This strategy is builds upon the previous two and is best suited for those of you who want complete control on the crawling and indexing of your site’s URLs and are not afraid to dive into analytical data.
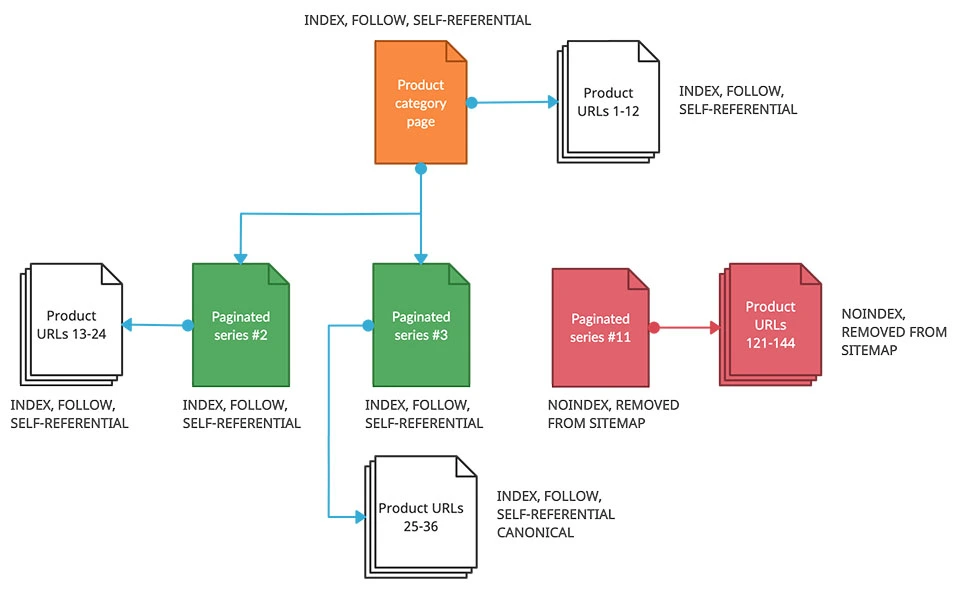
In essence, this strategy allows you to dictate which URLS are permitted to be paginated based on relevance, context, and timing.
Benefits:
- Crawling is prioritized for relevant URLs.
- Boost ranking signals via internal linking to search-intent relevant URLs only.
- Reduces the number of URLs to be indexed.
Disadvantages:
- Out of the 3 strategies, this requires the most effort as it is not a set-and-forget strategy.
How to do this:
- Allow indexing of all pagination URLs up until a certain timeframe (e.g., URLs older than 6 months are noindexed).
- Implement a process that rewrites the page title, meta description and H1 of paginated URLs to de-optimize them for the target keyword.
- Implement a rule so that pagination pages past 10 do not get indexed. This means applying a noindex metatag to all the pagination URLS that are greater than 10.
- At the same time, remove URLs from pagination series after a certain timeframe (e.g., 6 months) and remove the same URLs from your sitemap(s).
- Choose to 404 irrelevant URLs or 301 URLs that have been removed.
Additional resources.
This is the original presentation that Jes Scholz presented on Semrush.
I also recommend that you buy this ecommerce course by Luke Carthy on Blue Array Academy.
Closing remarks.
We have no control on how search engines rank our pages. Your goal is to minimise friction for search engines by leveraging factors that you can control.
This includes implementing directives for what a search engine can crawl, what it should index, and what it shouldn’t index. By doing this, you remove the guess work that a search engine has to make and as a result, the URLs you want to be shown on the SERPs have a better chance at showing up.