Technical SEO checklist: Suitable for all CMS and website platforms (e.g., WordPress, Shopify, AEM, Squarespace, Webflow, GatsbyJS etc)
🔗 Download the technical SEO checklist
The goal of technical SEO is to reduce all possible barriers that are making it difficult for search engines to discover pages, images, and other files that you want shown on search engine result pages.
But this is not realistic, for example:
- clients have budget constraints
- correcting legacy issues are cost-prohibitive and requires buy-in from stakeholders who are not involved in the current remit
- inadequate development or engineering resources.
Therefore, your job is to (i) identify all possible issues, then (ii) highlight mission-critical technical SEO issues and this checklist will allow you to do so.
Tools you will need to carry out your own technical SEO audit
- Software or app that can read and edit .xslx files
- Google Search Console of the site you are auditing
- Admin access to WordPress dashboard of the site you are auditing
- Screaming Frog SEO Spider (£149.00 per year license) or Sitebulb (from $13.50 per month)
- Web browser such as Chrome, Firefox, Safari to carry out manual checks
- Lighthouse
- SEO Pro Extension (free)
- Ahrefs (register for the free Webmaster version)
- Follow these instructions:
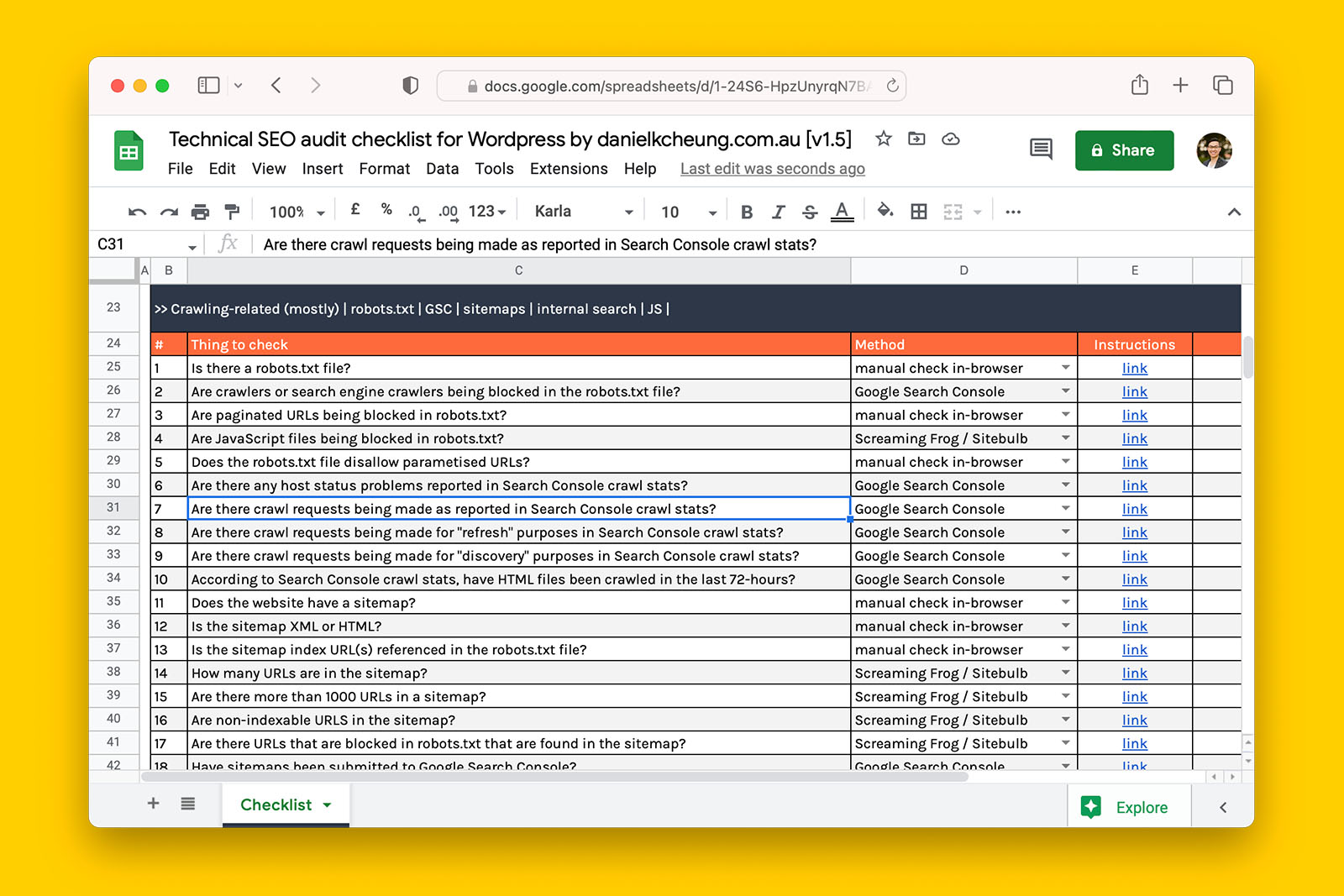
- How to audit a robots.txt file for crawling issues
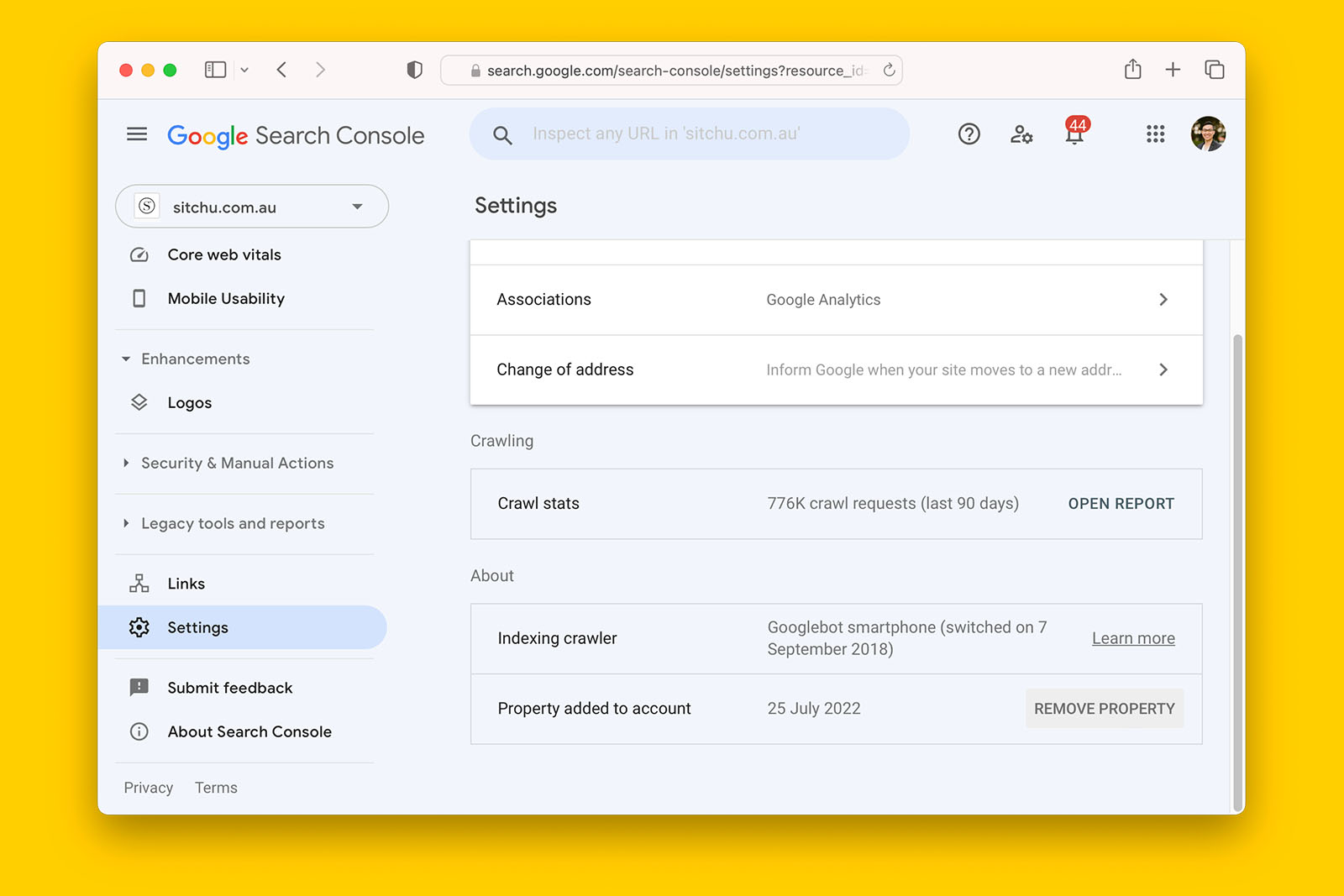
- How to use Search Console crawl stats to identify possible issues
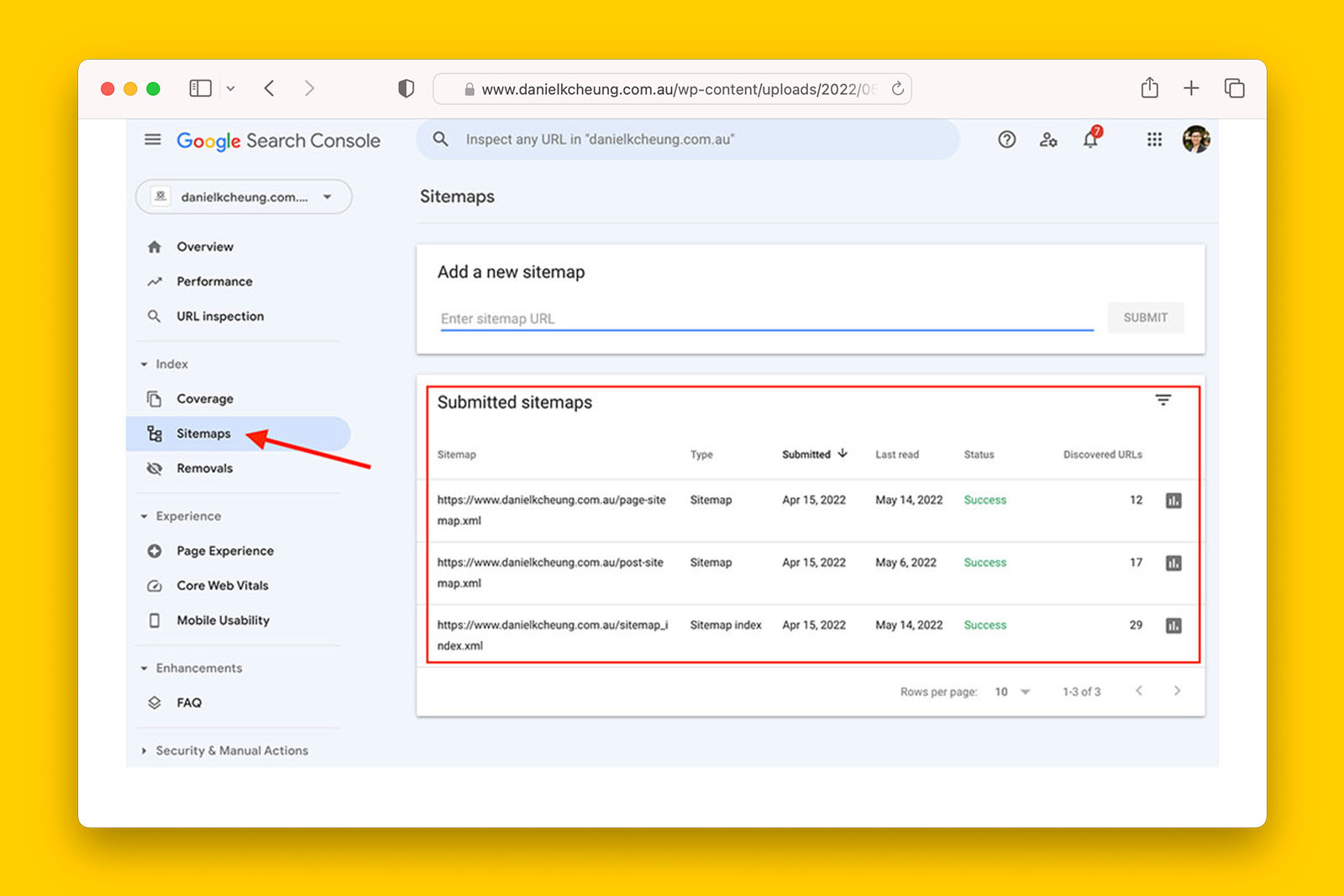
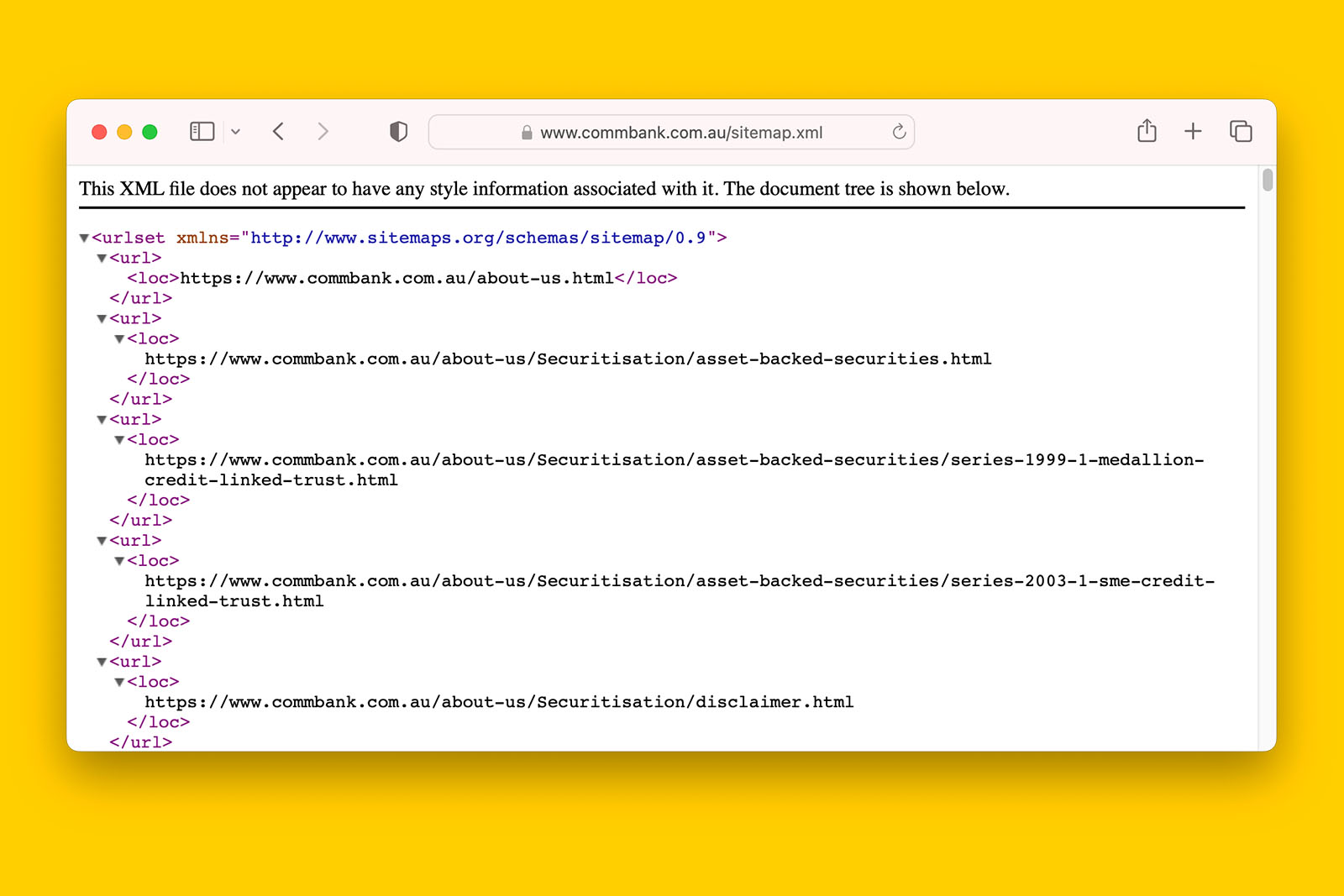
- How to audit a sitemap
- How to crawl a JavaScript website with Screaming Frog
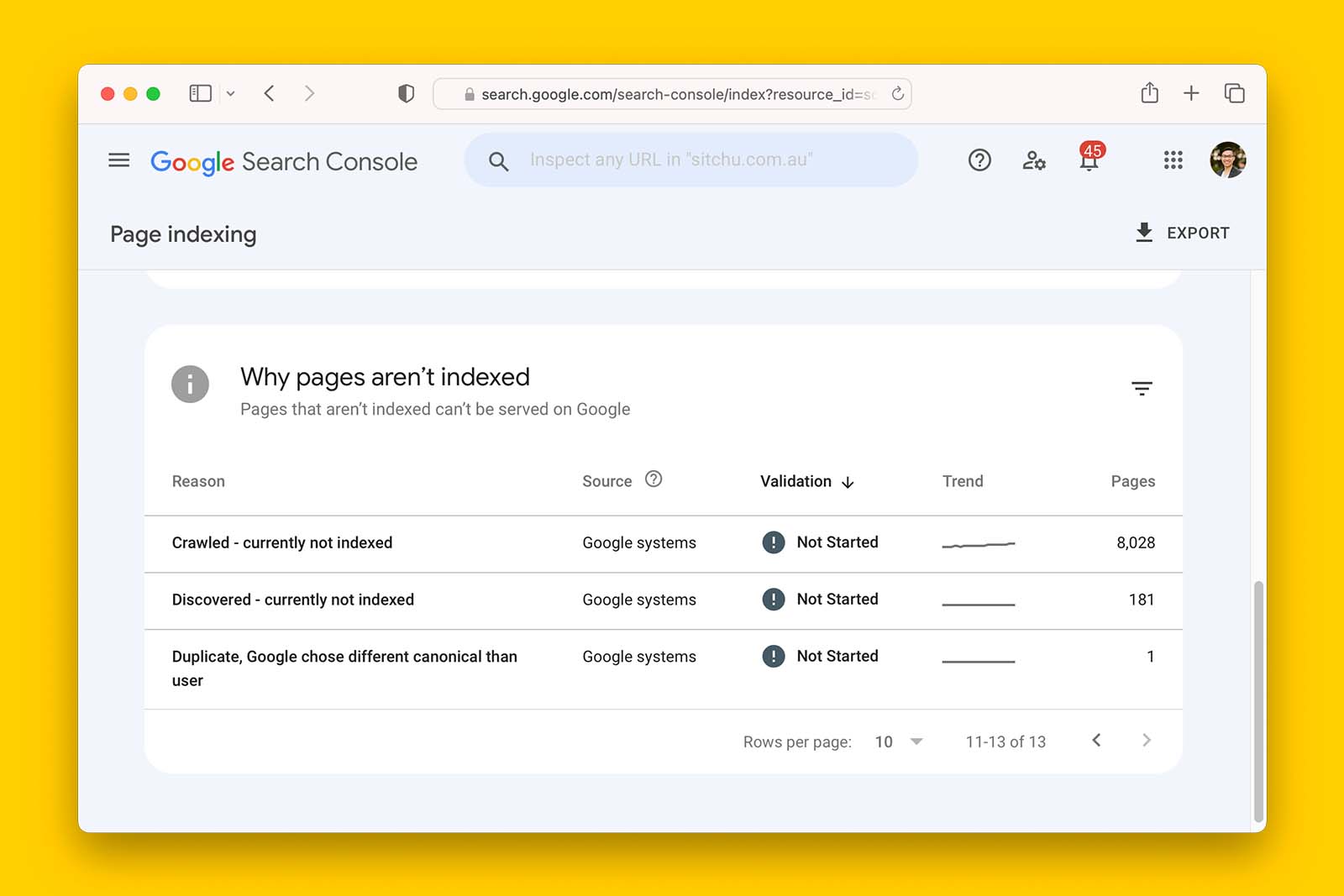
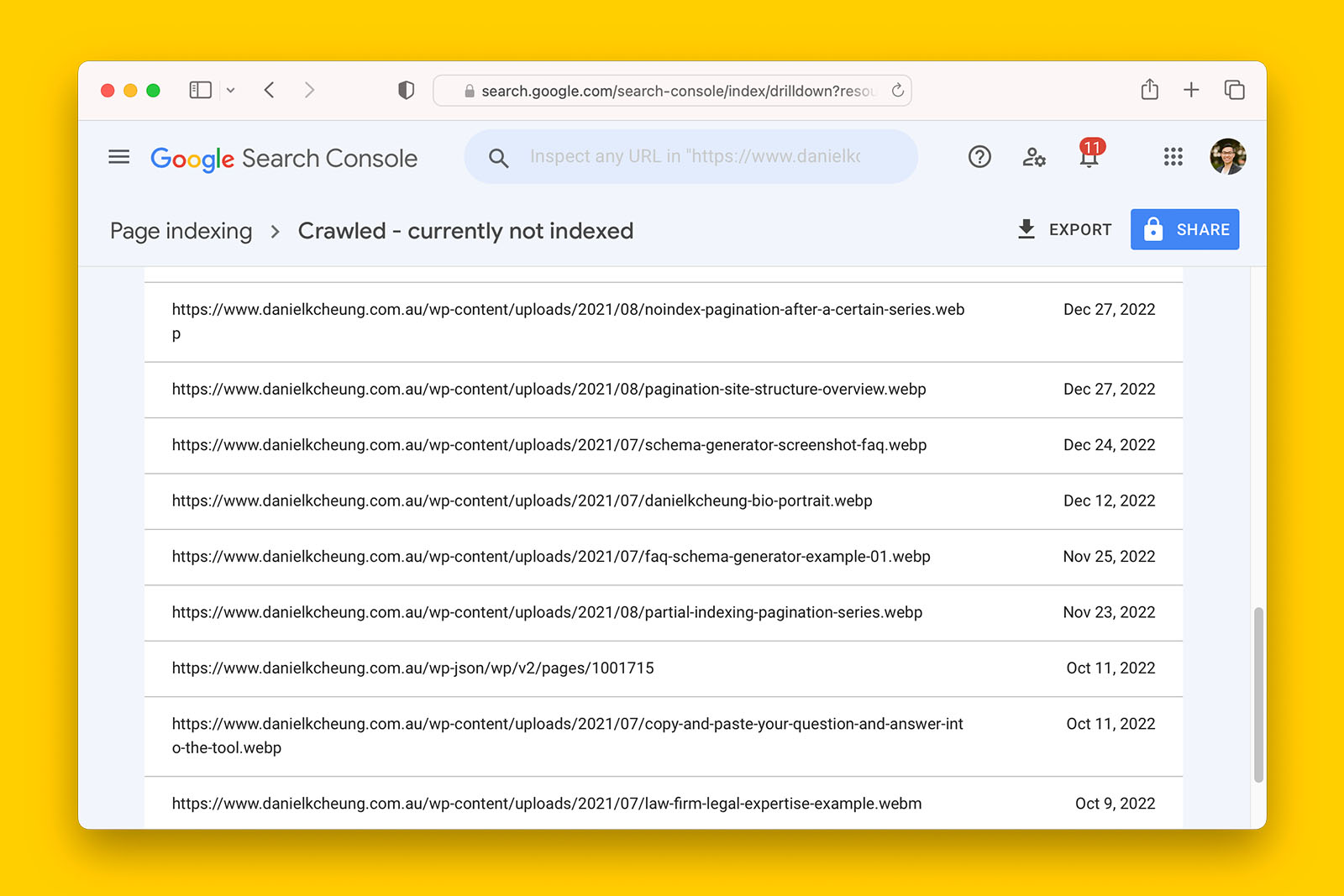
- Is there a trend of increasing URLs reported as “Crawled – currently not indexed” in Search Console index coverage?
Things you should know before you begin
- You do not need to check every criterion
- Depending on the purpose of your audit, what you hope to achieve, how much time you have, and what the final deliverable looks like, you may focus on a selection of criteria related to these variables
- While I created this checklist for auditing WordPress builds, you can use it for any CMS or platform
- Anyone can follow the instructions and I encourage beginners and SEO juniors/executives to give this a go
- Alternatively, learningseo.io and ContentKing Academy are recommended sources of SEO truth.
- For ecommerce applications, check out my product category page optimisation checklist.
Download the technical SEO checklist
Download the technical SEO checklist on Gumroad.
The checklist is available in the following languages:
- Arabic
- Czech
- English
- Greek (Eλληνικά)
- Hindi (हिन्दी)
- Indonesian
- Spanish